








数据库设计基础:简单来说,数据规范化的含义、关系型数据库中关系的目的、“一对多”关系。
数据规范化简单说
数据库的结构必须以不重复数据的方式来设计。在数据库管理系统中,这样做最方便的不是,而是使用诸如数据库设计的可视化数据库架构构建工具,以便整个数据库架构尽在掌握。
假设我们正在设计一个网上商店数据库的结构。我们需要存储销售的产品信息。此外,每个产品属于一个产品类别。我们该如何存储这些信息呢?
首先想到的可能是创建一个产品表格,在每个产品记录中存储其名称、描述、价格和类别名称:
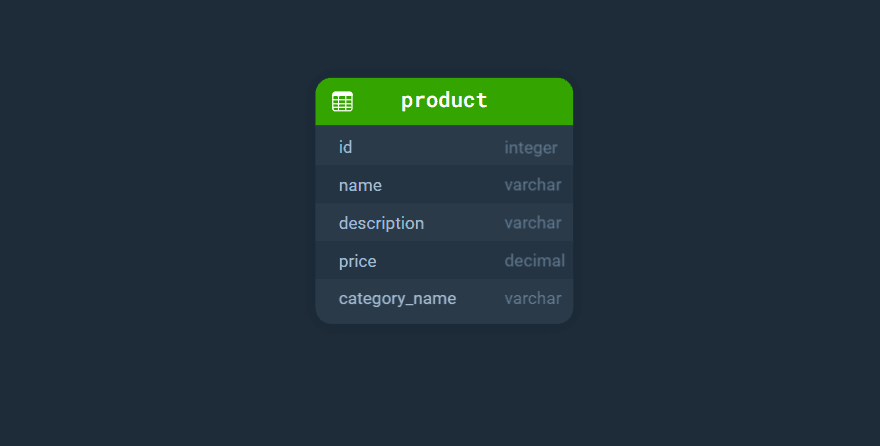 为什么这样做不好呢?想象一下,一个在线商店已经在运营,拥有许多类别和许多产品。需要更改其中一个类别的名称。利用这种实现,您必须在产品表中的每个记录中进行更改,将类别名称替换为新的名称。
为什么这样做不好呢?想象一下,一个在线商店已经在运营,拥有许多类别和许多产品。需要更改其中一个类别的名称。利用这种实现,您必须在产品表中的每个记录中进行更改,将类别名称替换为新的名称。
我们存储了大量相同的数据,且很难修改。此外,可能会发生这样的情况,在许多记录中更改类别名称的过程中过,数据库崩溃,部分名称未被更改。这将导致严重的数据不一致性,从而可能导致严重的错误。
那么我们该如何进行呢?让我们回到关系数据库的主要优势:创建表之间关系的能力。我们只需创建一个单独的表来存储类别数据。因此,当我们需要更改类别名称时,只会影响一条记录:
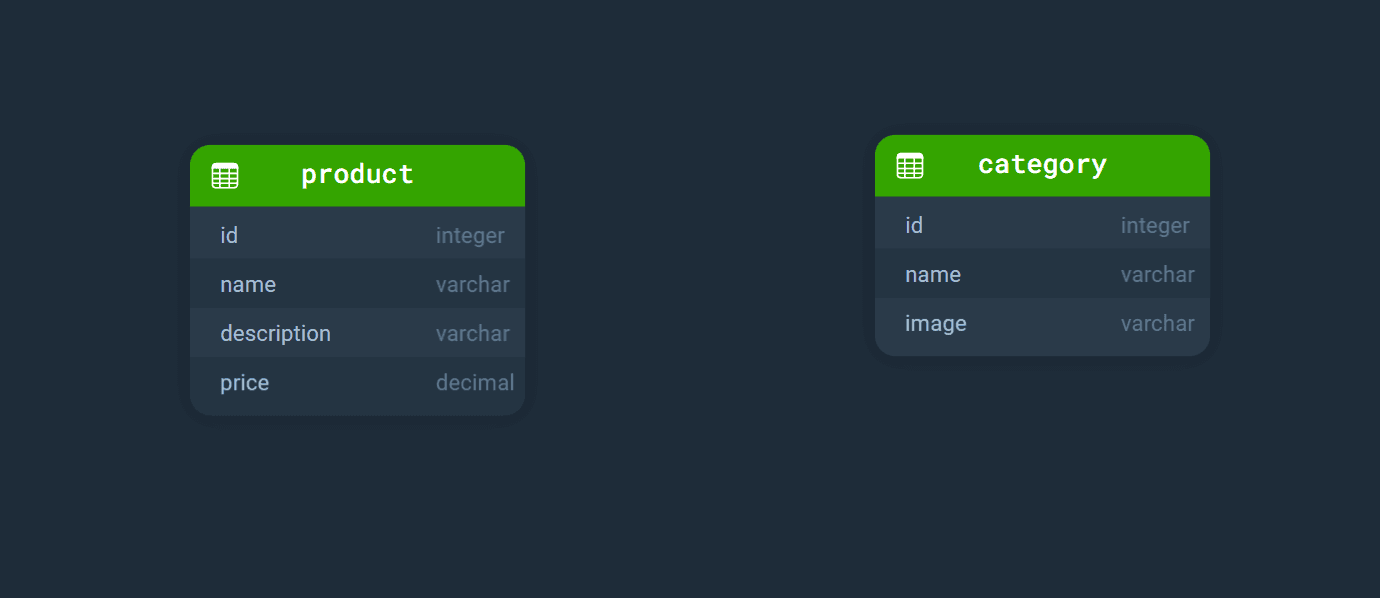
数据规范化结构是一个概念,其中绝对相同的数据不能在不同的记录中重复。这意味着当我们需要存储关于产品类别的信息时,我们将产品信息与类别信息分别存储。
那么我们如何理解某个产品属于哪个类别呢?我们需要在产品和类别之间建立关系。为此,我们在产品表中添加字段category_id,并在每个产品记录中存储该类别记录的id。
id是每条记录在任何表中都有的一个唯一(不重复)编号(除了多对多关系的表,但略后再谈)。在同一表中不能有两个相同的id,这使我们能够以100%的准确度通过其唯一编号来获取所需的记录。
看看它是怎么表现的:
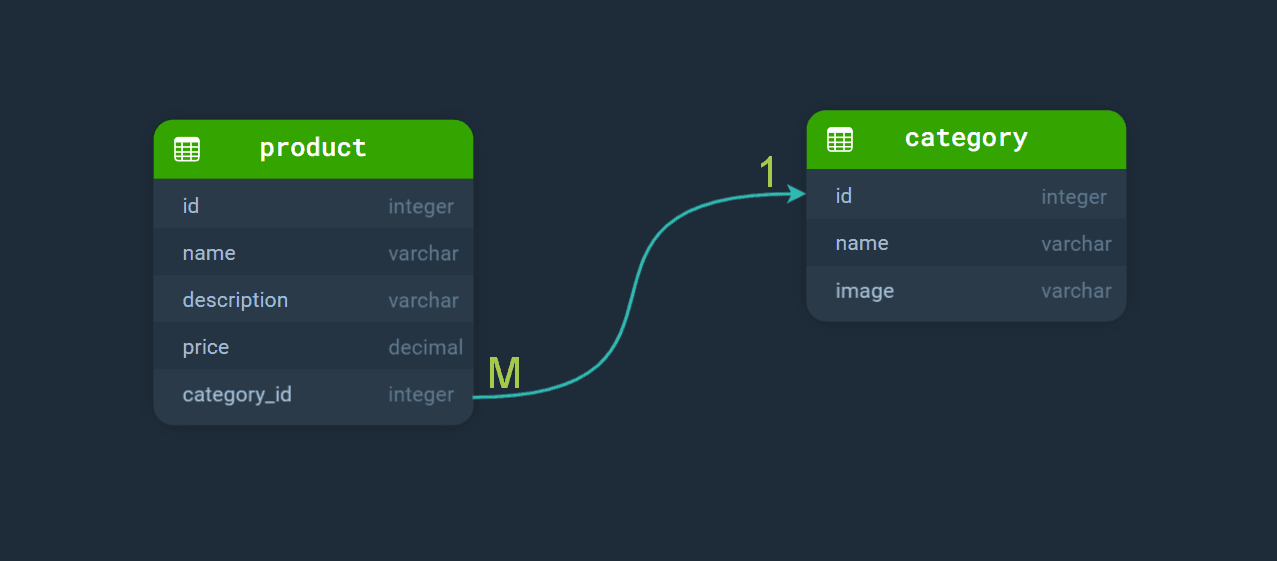 通过在产品记录中存储属于它们的类别的唯一编号,我们可以在获取每个产品时,也一起获取该类别的所有数据:
通过在产品记录中存储属于它们的类别的唯一编号,我们可以在获取每个产品时,也一起获取该类别的所有数据:
SELECT
p.id,
p.name,
p.description,
p.price,
c.id as 'category_id',
c.name as 'category_name',
c.image as 'category_image'
FROM
product p, category c
WHERE
p.category_id = c.id;
一对多的关系
在上图中,我们创建了“ 一对多”关系,也称为 one-to-many 或 1:М。同样,这是用示例来解释最简单:在我们的关系中,“ 一”是类别,而“ 多”是产品。
这意味着一个产品只能属于一个类别(adidas 的运动鞋只能是“ 鞋类”,而不是“ 手套” 或“ 帽子”)。与此同时,一个类别可以有多个产品(“ 鞋类” 中可以包括“ adidas 的运动鞋”、“ 皮靴”、“ nike 的运动鞋”等等)。
由于这种关系,我们提供了必要的逻辑,我在前面提供了一个例子。此外,当获取产品信息时,我们不仅可以获取类别的信息,还可以获取属于特定类别的产品列表。让我们扩展我们的 SQL 查询:
SELECT
p.id,
p.name,
p.description,
p.price,
c.id as 'category_id',
c.name as 'category_name',
c.image as 'category_image'
FROM
product p,
category c
WHERE
p.category_id = c.id
AND
c.id = N;
在 N 的位置,我们需要用类别的唯一编号来替换它。
在邻近的文章中,您可以找到有关其他类型的关系数据关系的信息:多对多和一对一。如果您觉得有用,可以通过点赞/评论/关注我的教育YouTube频道来支持我。
我在哪里可以设计数据库?
尝试使用新的可视化构造器,称为数据库设计。简单方便的界面使您能够以图形模型的可视化方式设计关系数据库,您可以链接来自不同表的字段,指示它们之间的关系。让我们看看它是什么样的:


数据库设计应用程序中的模式可以稍后导出为SQL转储,通过链接下载。转储文件可用于在任何正常的SQL数据库管理系统(DBMS)中重新创建关系数据库的确切结构,如MySQL。您甚至不需要为此编写SQL查询代码!
在数据库设计应用程序中工作是一种乐趣!
适用于专业人士和学生,用于组织存储和分析,以及可视化数据库模型以满足他们的项目需求。
在数据库设计中,您可以从浏览器进行工作,无需下载或安装任何东西!












